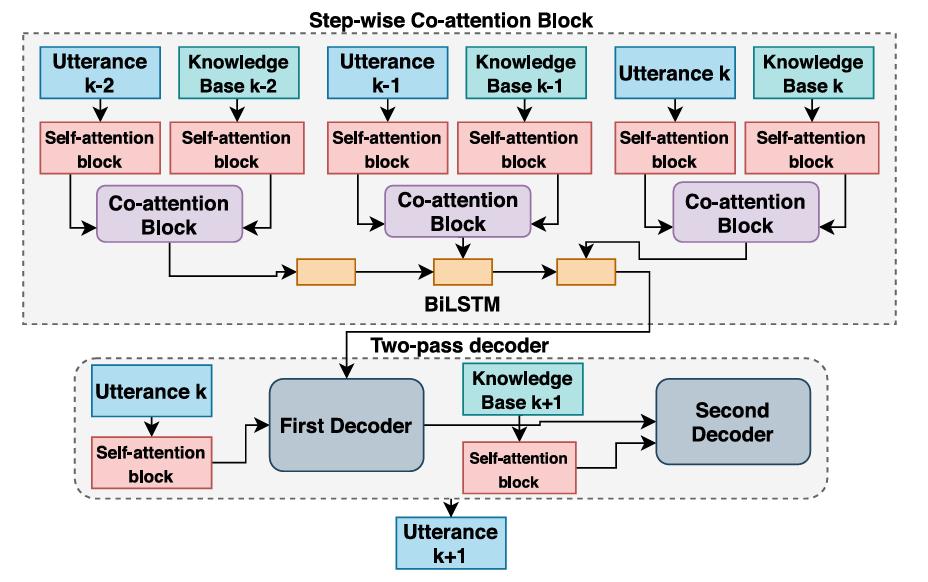
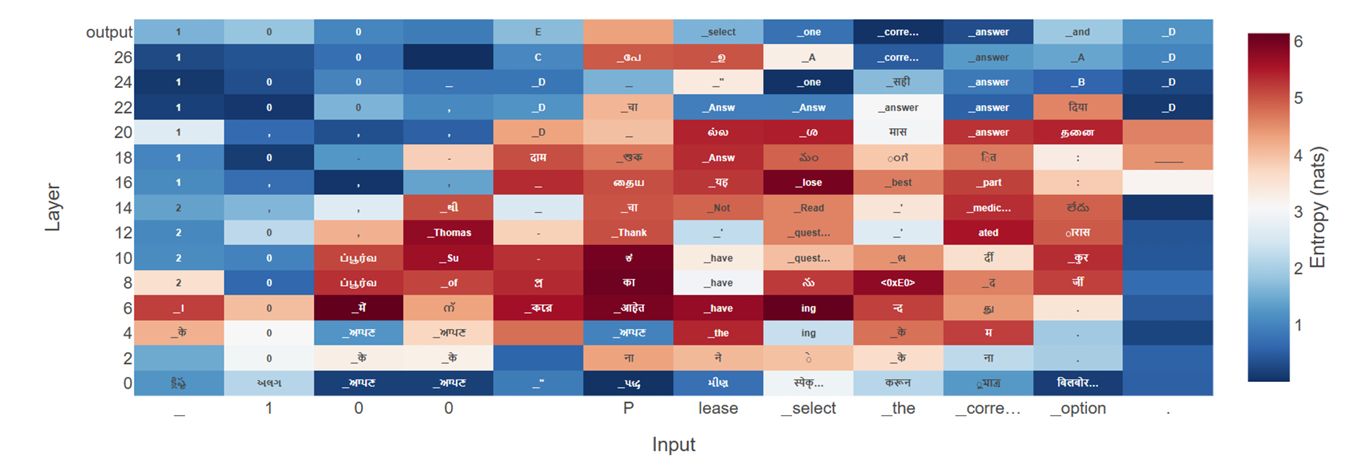
Multilingual large language models (LLMs) are increasingly deployed in linguistically diverse regions like India, yet most interpretability tools remain tailored to English. We introduce Indic-TunedLens, a novel interpretability framework specifically for Indian languages that learns shared affine transformations.
2025
ClimaEmpact: Domain-Aligned Small Language Models and Datasets for Extreme Weather Analytics
Deeksha Varshney, Keane Ong, Rui Mao, and 2 more authors
2025
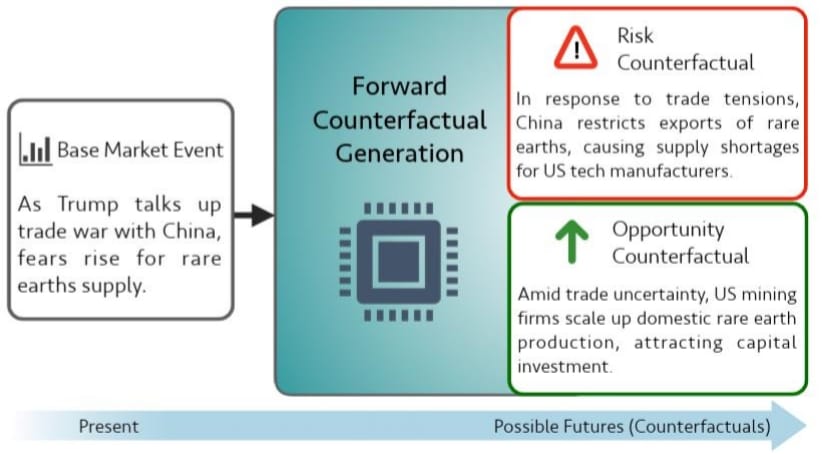
Deriving Strategic Market Insights with Large Language Models: A Benchmark for Forward Counterfactual Generation
Keane Ong, Rui Mao, Deeksha Varshney, and 3 more authors
Medical question-answering systems require the ability to extract accurate, concise, and comprehensive answers. They will better comprehend the complex text and produce helpful answers if they can reason on the explicit constraints described in the question’s textual context and the implicit, pertinent knowledge of the medical world. Integrating Knowledge Graphs (KG) with Language Models (LMs) is a common approach to incorporating structured information sources. However, effectively combining and reasoning over KG representations and language context remains an open question. To address this, we propose the Knowledge Infused Medical Question Answering system (KIMedQA), which employs two techniques viz. relevant knowledge graph selection and pruning of the large-scale graph to handle Vector Space Inconsistent (VSI) and Excessive Knowledge Information (EKI). The representation of the query and context are then combined with the pruned knowledge network using a pre-trained language model to generate an informed answer. Finally, we demonstrate through in-depth empirical evaluation that our suggested strategy provides cutting-edge outcomes on two benchmark datasets, namely MASH-QA and COVID-QA. We also compared our results to ChatGPT, a robust and very powerful generative model, and discovered that our model outperforms ChatGPT according to the F1 Score and human evaluation metrics such as adequacy.
Are my answers medically accurate? Exploiting medical knowledge graphs for medical question answering
Aizan Zafar, Deeksha Varshney, Sovan Kumar Sahoo, and 2 more authors
Poor health is one of the fundamental causes behind the suffering and deprivation of human beings. One of the United Nations (UN) Sustainable Development Goals is to enhance the quality of healthcare for everyone, which includes economic coverage, availability of high-quality fundamental health-care services, and access to proper, efficient, high-quality, and affordable important vaccinations and medications. Question-Answering (QA) in the medical domain has recently piqued the interest among the researchers and other stakeholders. Medical QA systems have the potential to enhance access to healthcare services, improve patient interactions with doctors, and reduce medical costs through e-medicine. In this paper, we describe a knowledge enabled QA model, which demonstrates how large-scale medical information in the form of knowledge graphs can aid in extracting more relevant answers. The proposed model employs two scoring methods, viz. Medical Entity Scoring (MES) and Context Relevance Scoring (CRS). MES ranks the medical entities from graphs according to their relevance, while CRS is used to reason over the supporting paragraph using the query vector. The system’s knowledge is obtained through the use of two distinct resources, viz. PharmKG is used for pharmaceutical terminology management, whereas Unified Medical Language System UMLS is used for general medical terminology management. Empirical results on the MASH-QA and COVID-QA datasets demonstrate that our proposed approach outperforms existing State-of-the-art in both machine evaluation and human judgment.
Yes, I am afraid of the sharks and also wild lions!: A multitask framework for enhancing dialogue generation via knowledge and emotion grounding
Current end-to-end neural conversation models inherently lack the capability to generate coherently engaging responses. Efforts to boost informativeness have an adversarial effect on emotional and factual accuracy, as validated by several sequence-based models. While these issues can be alleviated by access to emotion labels and background knowledge, there is no guarantee of relevance and informativeness in the generated responses. In real dialogue corpus, informative words like named entities, and words that carry specific emotions can often be infrequent and hard to model, and one primary challenge of the dialogue system is how to promote the model’s capability of generating high-quality responses with those informative words. Furthermore, earlier approaches depended on straightforward concatenation techniques that lacked robust representation capabilities in order to account for human emotions. To address this problem, we propose a novel multitask hierarchical encoder–decoder model, which can enhance the multi-turn dialogue response generation by incorporating external textual knowledge and relevant emotions. Experimental results on a benchmark dataset indicate that our model is superior over competitive baselines concerning both automatic and human evaluation.
Aspect-level sentiment-controlled knowledge grounded multimodal dialog generation using generative models for reviews
During a conversation, it is critical for participants to establish what they both agree on, also known as the common ground. Grounding implies recognizing that the listener has understood what the speaker has said, considering several factors. This can be accomplished by basing dialog models on various features like aspects, sentiments, images, and unstructured knowledge documents. The key innovation lies in our novel multi-modal knowledge-grounded context-aware transformer model, which enables a seamless fusion of textual and visual information. We introduce an effective technique for generating reviews based on the user’s aspect and sentiment (i.e., aspect-level sentiment-controllable reviews), which serves as the relevant external knowledge for the dialog systems. Our work highlights the importance of incorporating review expertise in knowledge-based multi-modal dialog generation. We utilize the Knowledge Grounded Multi-Modal Dialog (KGMMD) dataset, which includes dial og utterances accompanied by images, aspects, sentiment, and unstructured knowledge in the form of several long hotel reviews for different hotels mentioned in the dataset. The overall framework consists of a dialog encoder, a review generator, and a response decoder, all of which complement one another by generating appropriate reviews, which eventually assist in generating an adequate response. The proposed model outperforms the baseline models for aspect-level sentiment-controlled knowledge-based multimodal response generation with a significant increase in F1-score (13.3%) and BLEU-4 (5.3%) on the KGMMD dataset
2023
Knowledge graph assisted end-to-end medical dialog generation
Deeksha Varshney, Aizan Zafar, Niranshu Kumar Behera, and 1 more author
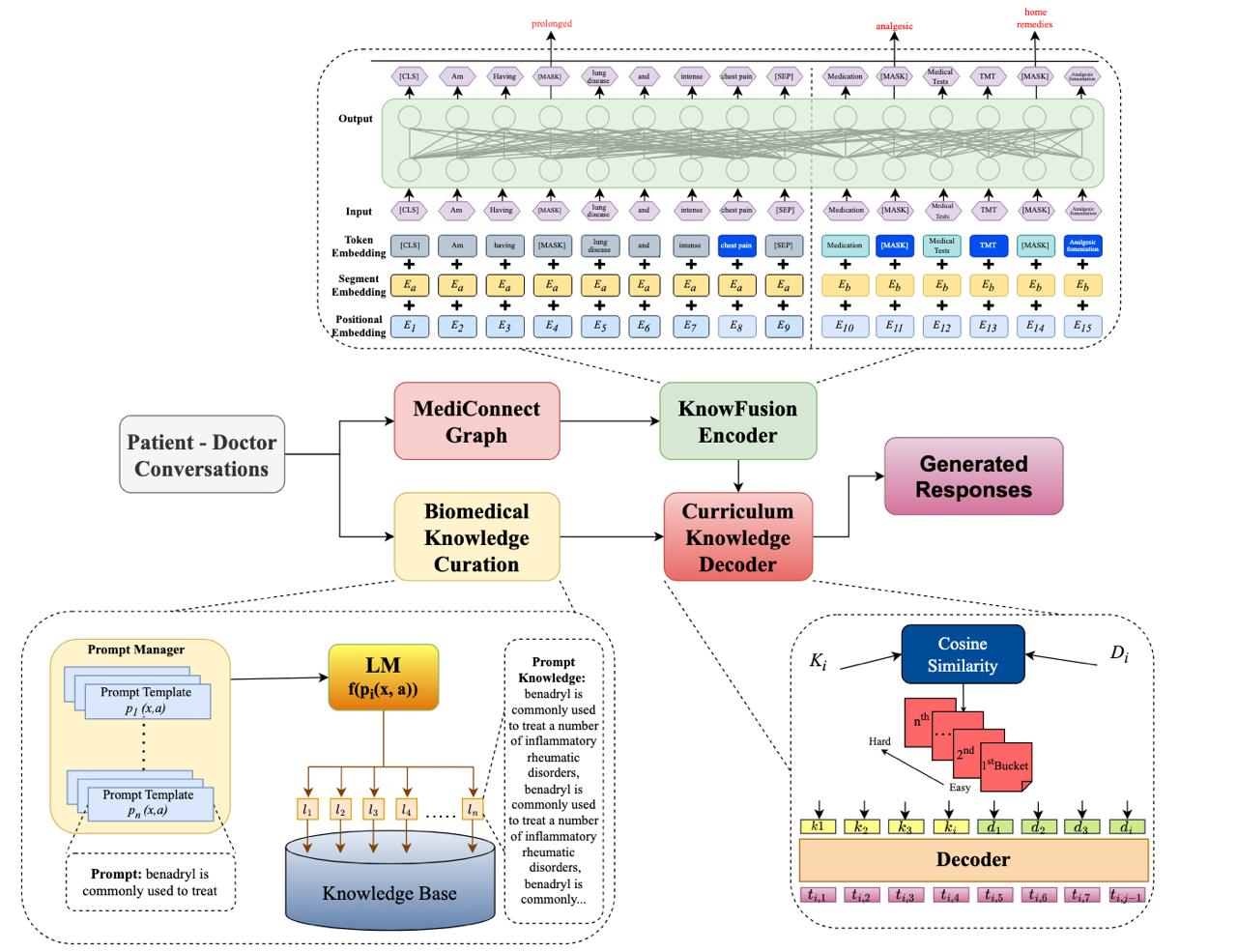
Medical dialog systems have the potential to assist e-medicine in improving access to healthcare services, improving patient treatment quality, and lowering medical expenses. In this research, we describe a knowledge-grounded conversation generation model that demonstrates how large-scale medical information in the form of knowledge graphs can aid in language comprehension and generation in medical dialog systems. Generic responses are often produced by existing generative dialog systems, resulting in monotonous and uninteresting conversations. To solve this problem, we combine various pre-trained language models with a medical knowledge base (UMLS) to generate clinically correct and human-like medical conversations using the recently released MedDialog-EN dataset. The medical-specific knowledge graph contains broadly 3 types of medical-related information, including disease, symptom and laboratory test. We perform reasoning over the retrieved knowledge graph by reading the triples in each graph using MedFact attention, which allows us to use semantic information from the graphs for better response generation. In order to preserve medical information, we employ a policy network, which effectively injects relevant entities associated with each dialog into the response. We also study how transfer learning can significantly improve the performance by utilizing a relatively small corpus, created by extending the recently released CovidDialog dataset, containing the dialogs for diseases that are symptoms of Covid-19. Empirical results on the MedDialog corpus and the extended CovidDialog dataset demonstrate that our proposed model significantly outperforms the state-of-the-art methods in terms of both automatic evaluation and human judgment.
Knowledge grounded medical dialogue generation using augmented graphs
Deeksha Varshney, Aizan Zafar, Niranshu Kumar Behera, and 1 more author
Smart healthcare systems that make use of abundant health data can improve access to healthcare services, reduce medical costs and provide consistently high-quality patient care. Medical dialogue systems that generate medically appropriate and human-like conversations have been developed using various pre-trained language models and a large-scale medical knowledge base based on Unified Medical Language System (UMLS). However, most of the knowledge-grounded dialogue models only use local structure in the observed triples, which suffer from knowledge graph incompleteness and hence cannot incorporate any information from dialogue history while creating entity embeddings.
EmoKbGAN: Emotion controlled response generation using Generative Adversarial Network for knowledge grounded conversation
Deeksha Varshney, Asif Ekbal, M. Tiwari, and 1 more author
Neural open-domain dialogue systems often fail to engage humans in long-term interactions on popular topics such as sports, politics, fashion, and entertainment. However, to have more socially engaging conversations, we need to formulate strategies that consider emotion, relevant-facts, and user behaviour in multi-turn conversations. Establishing such engaging conversations using maximum likelihood estimation (MLE) based approaches often suffer from the problem of exposure bias. Since MLE loss evaluates the sentences at the word level, we focus on sentence-level judgment for our training purposes. In this paper, we present a method named EmoKbGAN for automatic response generation that makes use of the Generative Adversarial Network (GAN) in multiple-discriminator settings involving joint minimization of the losses provided by each attribute specific discriminator model (knowledge and emotion discriminator). Experimental results on two bechmark datasets i.e the Topical Chat and Document Grounded Conversation dataset yield that our proposed method significantly improves the overall performance over the baseline models in terms of both automated and human evaluation metrics, asserting that the model can generate fluent sentences with better control over emotion and content quality.
Distraction-free Embeddings for Robust VQA
Atharvan Dogra, Deeksha Varshney, Ashwin Kalyan, and 2 more authors
The generation of effective latent representations and their subsequent refinement to incorporate precise information is an essential prerequisite for Vision-Language Understanding (VLU) tasks such as Video Question Answering (VQA). However, most existing methods for VLU focus on sparsely sampling or fine-graining the input information (e.g., sampling a sparse set of frames or text tokens), or adding external knowledge. We present a novel "DRAX: Distraction Removal and Attended Cross-Alignment" method to rid our cross-modal representations of distractors in the latent space. We do not exclusively confine the perception of any input information from various modalities but instead use an attention-guided distraction removal method to increase focus on task-relevant information in latent embeddings. DRAX also ensures semantic alignment of embeddings during cross-modal fusions. We evaluate our approach on a challenging benchmark (SUTD-TrafficQA dataset), testing the framework’s abilities for feature and event queries, temporal relation understanding, forecasting, hypothesis, and causal analysis through extensive experiments.
2022
Commonsense and Named Entity Aware Knowledge Grounded Dialogue Generation
Deeksha Varshney, Akshara Prabhakar, and Asif Ekbal
Emotion Recognition in Conversation (ERC) is becoming increasingly popular due to the accessibility of an enormous measure of openly accessible conversational information. Moreover, it has potential applications in opinion mining, social media and the health care domain. In this paper, we propose a novel Context and Knowledge Enriched Transformer Framework (CKETF) in which we interpret the contextual information from the utterances using a pre-trained Bidirectional Encoder Representations from Transformers (BERT) model and leverage additive attention based hierarchical transformer for encoding the knowledge sentences. Experiments on the knowledge-grounded Topical Chat dataset shows that both context and external knowledge are important for conversational emotion recognition. We demonstrate through extensive experiments and analysis that our proposed model significantly outperforms the current state-of-the-art methods.
CDialog: A multi-turn covid-19 conversation dataset for entity-aware dialog generation
Deeksha Varshney, Aizan Zafar, Niranshu Behera, and 1 more author
In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Dec 2022
In natural language understanding (NLU) production systems, users’ evolving needs necessitate the addition of new features over time, indexed by new symbols added to the meaning representation space. This requires additional training data and results in ever-growing datasets. We present the first systematic investigation into this incremental symbol learning scenario. Our analysis reveals a troubling quirk in building broad-coverage NLU systems: as the training dataset grows, performance on a small set of new symbols often decreases. We show that this trend holds for multiple mainstream models on two common NLU tasks: intent recognition and semantic parsing. Rejecting class imbalance as the sole culprit, we reveal that the trend is closely associated with an effect we call source signal dilution, where strong lexical cues for the new symbol become diluted as the training dataset grows. Selectively dropping training examples to prevent dilution often reverses the trend, showing the over-reliance of mainstream neural NLU models on simple lexical cues.
2021
Modelling Context Emotions using Multi-task Learning for Emotion Controlled Dialog Generation
Deeksha Varshney, Asif Ekbal, and Pushpak Bhattacharyya
In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Apr 2021
A recent topic of research in natural language generation has been the development of automatic response generation modules that can automatically respond to a user’s utterance in an empathetic manner. Previous research has tackled this task using neural generative methods by augmenting emotion classes with the input sequences. However, the outputs by these models may be inconsistent. We employ multi-task learning to predict the emotion label and to generate a viable response for a given utterance using a common encoder with multiple decoders. Our proposed encoder-decoder model consists of a self-attention based encoder and a decoder with dot product attention mechanism to generate response with a specified emotion. Human evaluation reveals that our model produces more emotionally pertinent responses.
Context and Knowledge Enriched Transformer Framework for Emotion Recognition in Conversations
Soumitra Ghosh, Deeksha Varshney, Asif Ekbal, and 1 more author
In 2021 International Joint Conference on Neural Networks (IJCNN), 2021
Emotion Recognition in Conversation (ERC) is becoming increasingly popular due to the accessibility of an enormous measure of openly accessible conversational information. Moreover, it has potential applications in opinion mining, social media and the health care domain. In this paper, we propose a novel Context and Knowledge Enriched Transformer Framework (CKETF) in which we interpret the contextual information from the utterances using a pre-trained Bidirectional Encoder Representations from Transformers (BERT) model and leverage additive attention based hierarchical transformer for encoding the knowledge sentences. Experiments on the knowledge-grounded Topical Chat dataset shows that both context and external knowledge are important for conversational emotion recognition. We demonstrate through extensive experiments and analysis that our proposed model significantly outperforms the current state-of-the-art methods.
Knowledge grounded multimodal dialog generation in task-oriented settings
Deeksha Varshney, Asif Ekbal, and Anushkha Singh
In Proceedings of the 35th Pacific Asia Conference on Language, Information and Computation, 2021
Smart healthcare systems that make use of abundant health data can improve access to healthcare services, reduce medical costs and provide consistently high-quality patient care. Medical dialogue systems that generate medically appropriate and human-like conversations have been developed using various pre-trained language models and a large-scale medical knowledge base based on Unified Medical Language System (UMLS). However, most of the knowledge-grounded dialogue models only use local structure in the observed triples, which suffer from knowledge graph incompleteness and hence cannot incorporate any information from dialogue history while creating entity embeddings. As a result, the performance of such models decreases significantly. To address this problem, we propose a general method to embed the triples in each graph into large-scalable models and thereby generate clinically correct responses based on the conversation history using the recently recently released MedDialog(EN) dataset. Given a set of triples, we first mask the head entities from the triples overlapping with the patient’s utterance and then compute the cross-entropy loss against the triples’ respective tail entities while predicting the masked entity. This process results in a representation of the medical concepts from a graph capable of learning contextual information from dialogues, which ultimately aids in leading to the gold response. We also fine-tune the proposed Masked Entity Dialogue (MED) model on smaller corpora which contain dialogues focusing only on the Covid-19 disease named as the Covid Dataset. In addition, since UMLS and other existing medical graphs lack data-specific medical information, we re-curate and perform plausible augmentation of knowledge graphs using our newly created Medical Entity Prediction (MEP) model. Empirical results on the MedDialog(EN) and Covid Dataset demonstrate that our proposed model outperforms the state-of-the-art methods in terms of both automatic and human evaluation metrics.
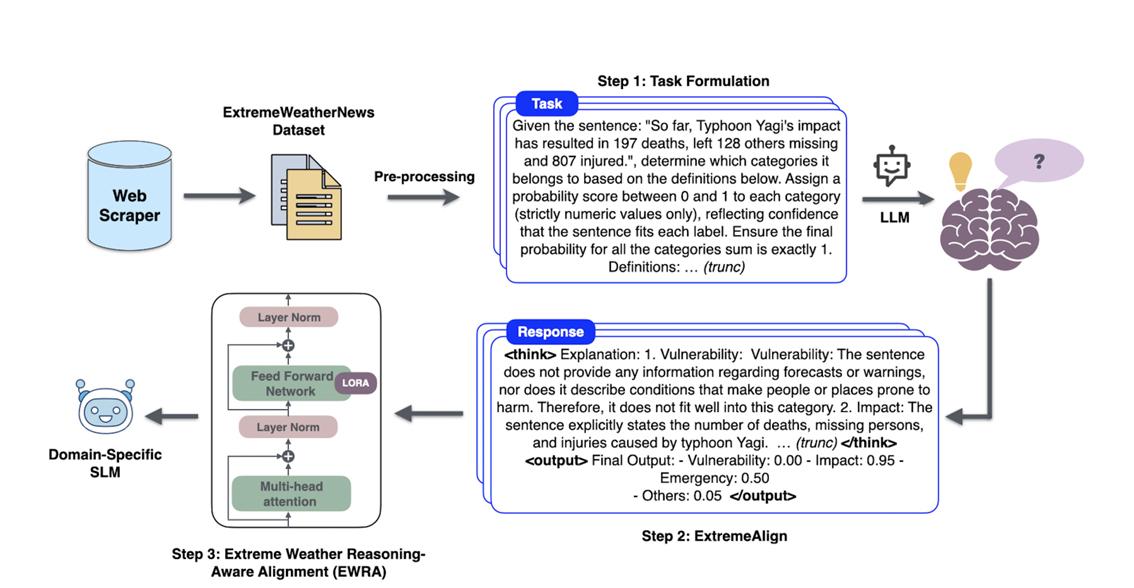 ClimaEmpact: Domain-Aligned Small Language Models and Datasets for Extreme Weather Analytics2025
ClimaEmpact: Domain-Aligned Small Language Models and Datasets for Extreme Weather Analytics2025